Object storage in Windmill (S3)
Instance and workspace object storage are different from using S3 resources within scripts, flows, and apps, which is free and unlimited.
At the workspace level, what is exclusive to the Enterprise version is using the integration of Windmill with S3 that is a major convenience layer to enable users to read and write from S3 without having to have access to the credentials.
Additionally, for instance integration, the Enterprise version offers advanced features such as large-scale log management and distributed dependency caching.

Workspace object storage is also used as the backend for volumes, which provide persistent file storage for scripts.
Workspace object storage
Connect your Windmill workspace to your S3 bucket, Azure Blob storage, or GCS bucket to enable users to read and write from S3 without having to have access to the credentials. When you reference S3 objects in your code, Windmill automatically tracks these data flows through the Assets feature for better pipeline visibility.

Windmill S3 bucket browser will not work for buckets containing more than 20 files and uploads are limited to files < 50MB. Consider upgrading to Windmill Enterprise Edition to use this feature with large buckets.
Once you've created an S3, Azure Blob, or Google Cloud Storage resource in Windmill, go to the workspace settings > S3 Storage. Select the resource and click Save.
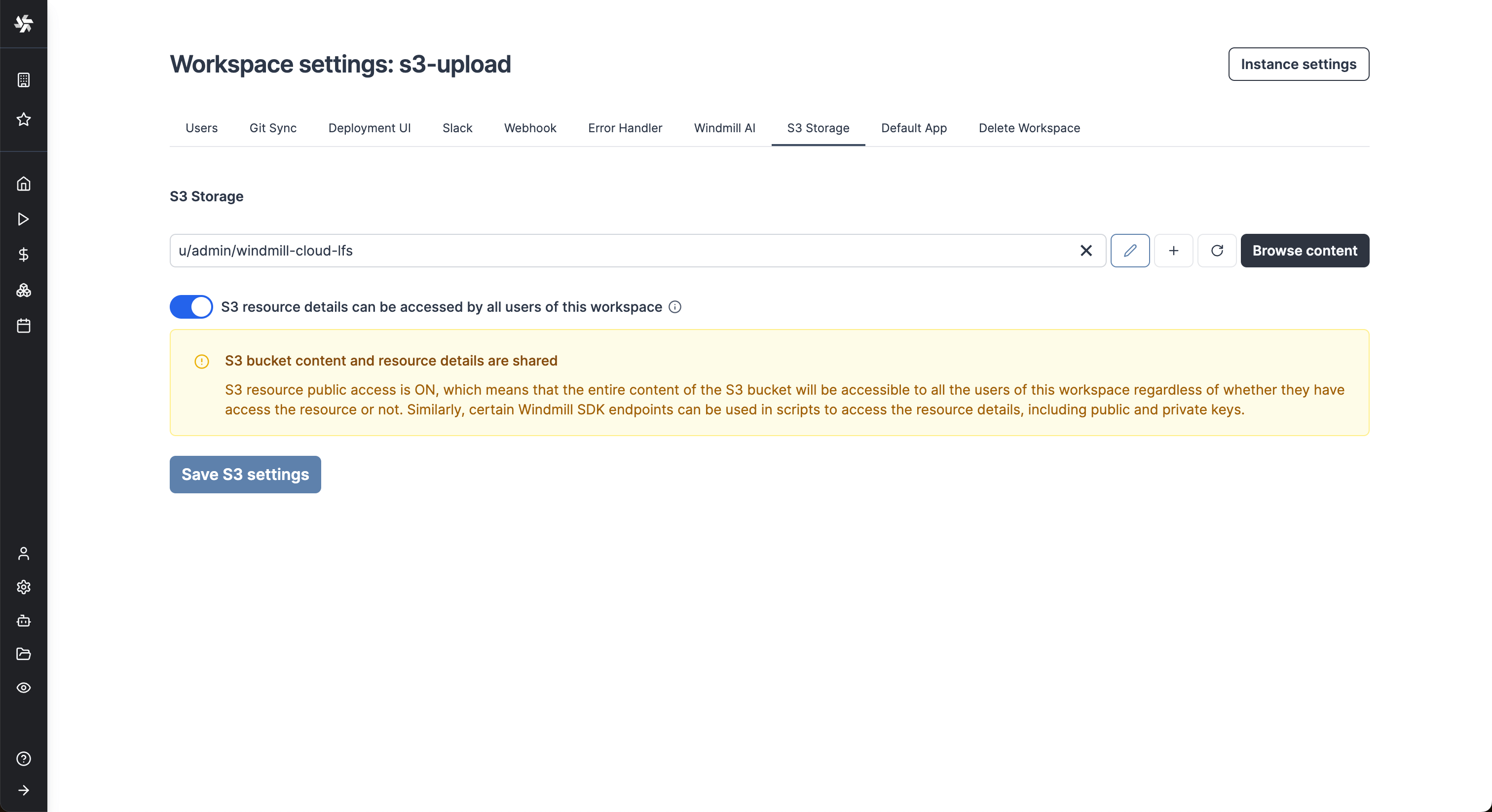
From now on, Windmill will be connected to this bucket and you'll have easy access to it from the code editor and the job run details. If a script takes as input a s3object, you will see in the input form on the right a button helping you choose the file directly from the bucket.
Same for the result of the script. If you return an s3object containing a key s3 pointing to a file inside your bucket, in the result panel there will be a button to open the bucket explorer to visualize the file.
S3 files in Windmill are just pointers to the S3 object using its key. As such, they are represented by a simple JSON:
{
"s3": "path/to/file"
}
Resources permissions
Advanced S3 permissions are only available on Enterprise Edition. Without advanced permissions, all users have R/W to all files on an S3 workspace storage, but they cannot list them
When you configure a workspace storage, you can enable advanced permissions to finely control which users can access which files in the bucket. The default rules enforce that users can only access files in S3 in paths that they would have access to in Windmill.
For example, user alice can access files in the path u/alice/**/* and files shared with her in g/group1/**/* if she is part of group1. If she has read-only access to folder1, and she tries to access the s3 object at path, f/folder1/file.csv, she will only be able to read the file, not write or delete it.
These rules are enforced when accessing data with the Windmill client (e.g in Typescript or Python), or from the Windmill S3 Proxy (used by DuckDB scripts).

You can customise these rules however you'd like. The rules are read in order, and the first one to match decides of the access. If no rules match, the access is denied. We support the unix glob syntax (**, *, ?, {a,b} ...)
You can use interpolated variables like {username}, which will be replaced by the current user's username. A rule might get transformed to multiple ones, for example, for a user in group1 and group2, the rule g/{group}/**/* will expand to ['g/group1/**/*', 'g/group2/**/*'].
Admins can always access everything.
All interactions with the S3 bucket are proxied through Windmill's backend. We guarantee that users who don't have access to the resource won't be able to retrieve any of its details (access key and secret key), unless the lecacy public mode is enabled (see below).
The resource can be set to be public by disabling advanced permissions which will show the "S3 resource details can be accessed by all users of this workspace" toggle.
In this case, permissions will be ignored when users interact with the S3 bucket via Windmill. Note that when the resource is public, the users might be able to access all of its details (including access keys and secrets) via some Windmill endpoints.
S3 input and output UI
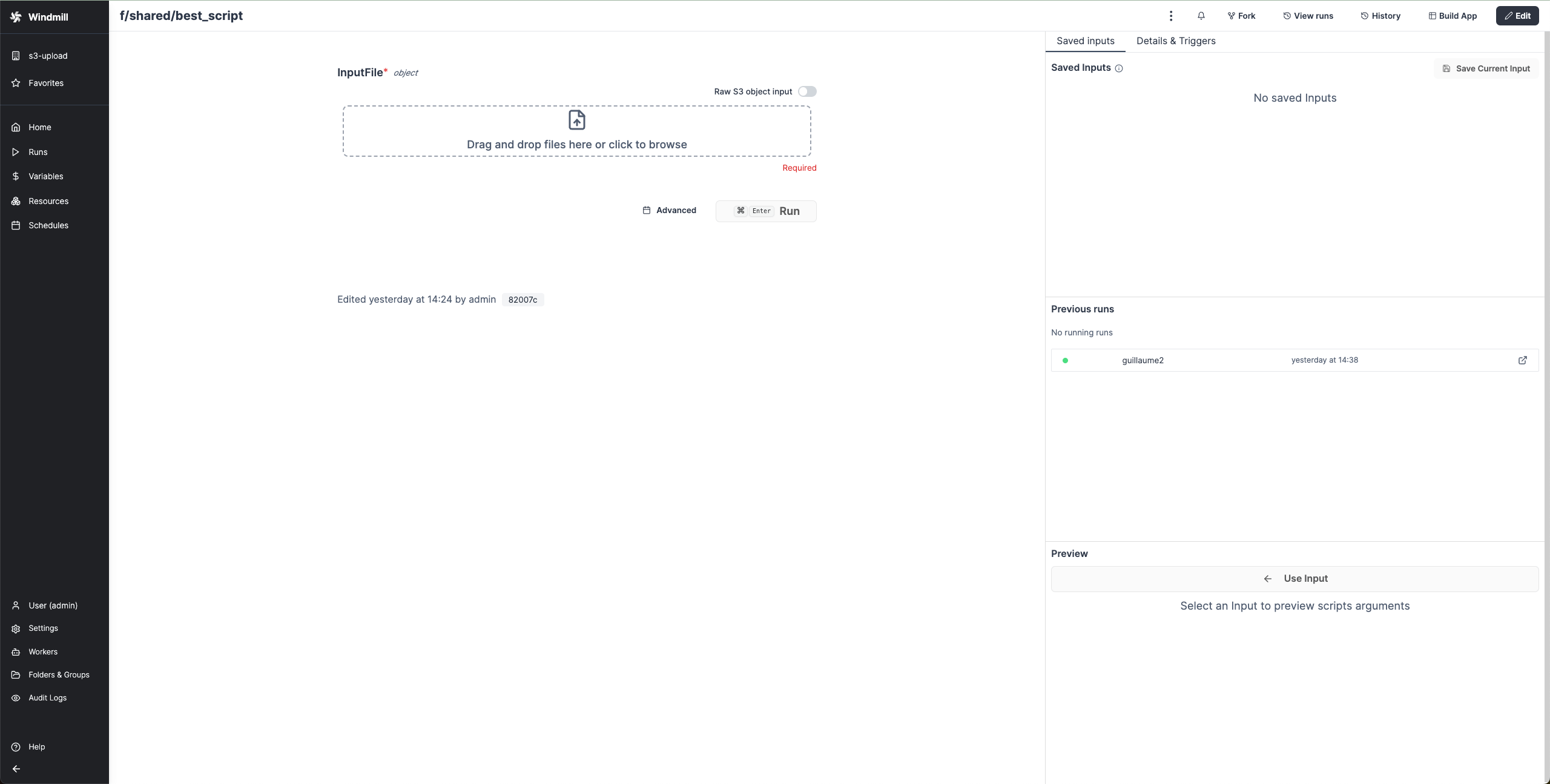
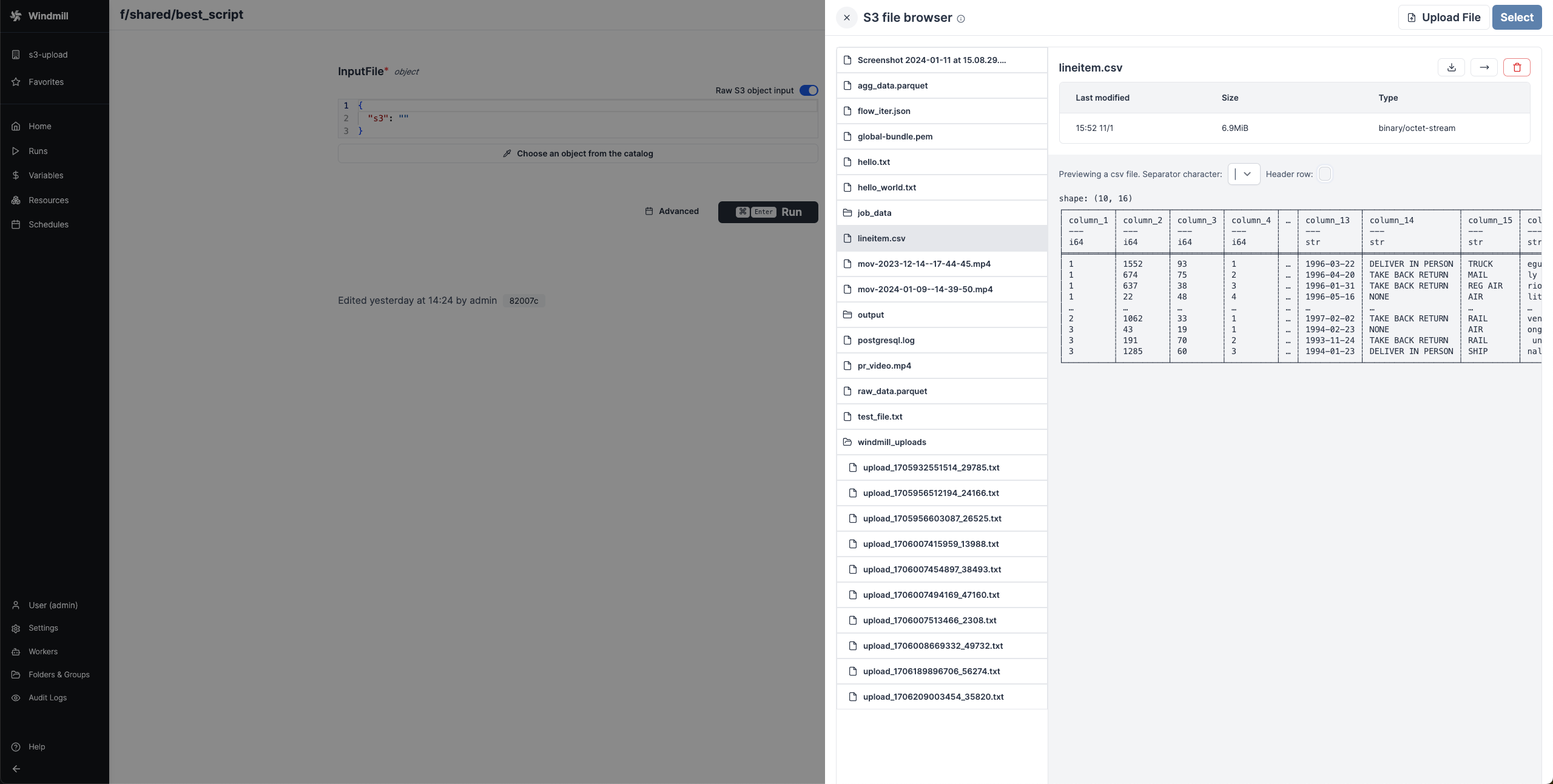
When a script accepts a S3 file as input, it can be directly uploaded or chosen from the bucket explorer.
When a script outputs a S3 file, it can be downloaded or previewed directly in Windmill's UI (for displayable files like text files, CSVs, images, PDFs, and parquet files).
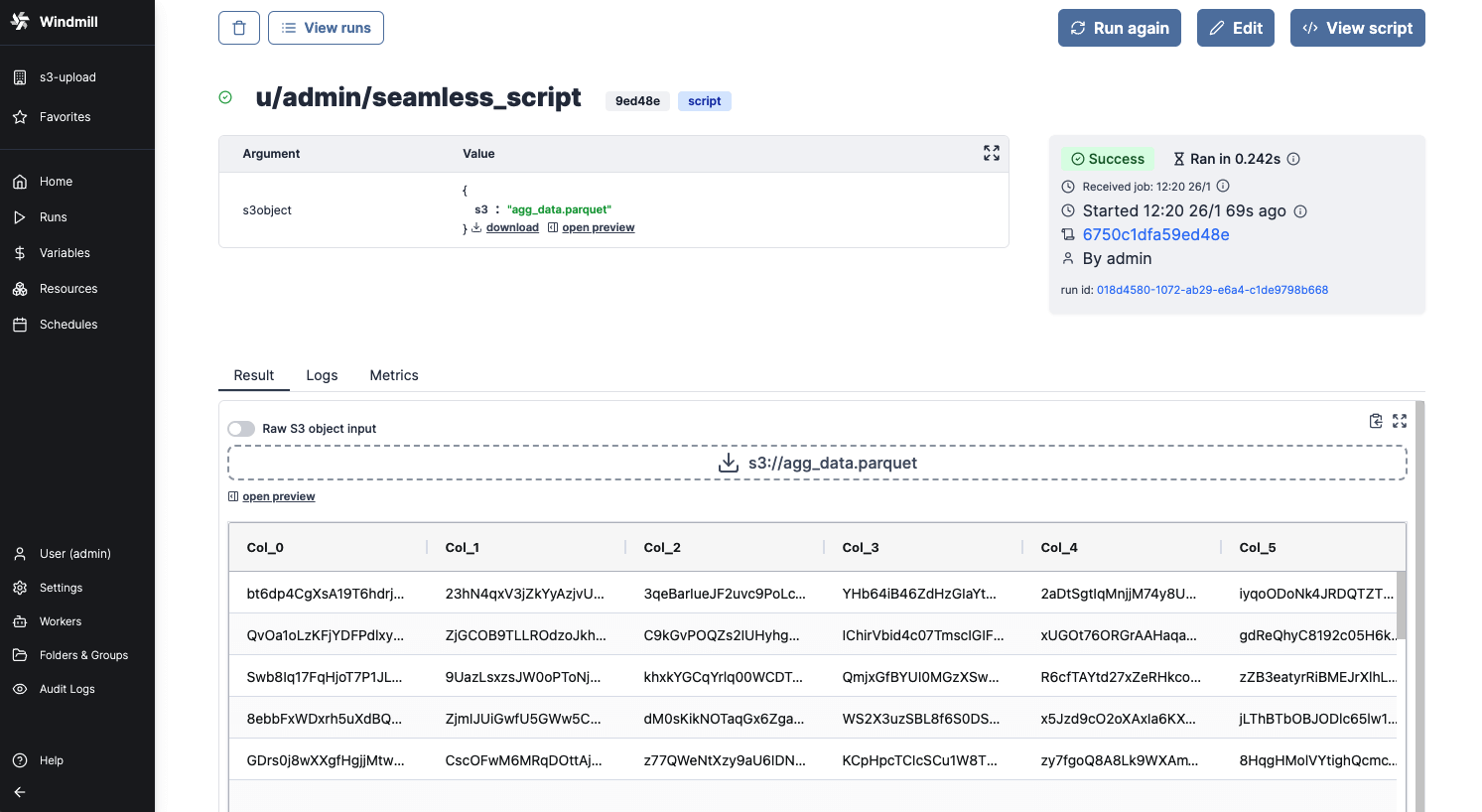
Even though the whole file is downloadable, the backend only sends the rows that the frontend needs for the preview. This means that you can manipulate objects of infinite size, and the backend will only return what is necessary.
You can even display several S3 files through an array of S3 objects:
export async function main() {
return [{s3: "path/to/file_1"}, {s3: "path/to/file_2", {s3: "path/to/file_3"}}];
}

Rendering JSON files straight from S3 is not supported. Instead you can load the file and parse it as a JSON object and return it as a rich result.
Read a file from S3 or object storage within a script
S3Object is a type that represents a file in S3 or object storage.
S3 files in Windmill are just pointers to the S3 object using its key. As such, they are represented by a simple JSON:
{
"s3": "path/to/file"
}
You can read a file from S3 or object storage within a script using the loadS3File and loadS3FileStream functions from the TypeScript client and the wmill.load_s3_file and wmill.load_s3_file_stream functions from the Python client. When writing or manipulating file content, consider using Blob objects to efficiently handle binary data and ensure compatibility across different file types.
loadS3File: This function loads the entire file content into memory as a single unit, which is useful for smaller files where you need immediate access to all data.loadS3FileStream: This function provides a stream of the file content, allowing you to process large files incrementally without loading the entire file into memory, which is ideal for handling large datasets or files.
- TypeScript (Bun)
- TypeScript (Deno)
- Python
import * as wmill from 'windmill-client';
import { S3Object } from 'windmill-client';
export async function main() {
const example_file: S3Object = {
s3: 'path/to/file'
};
// Load the entire file_content as a Uint8Array
const file_content = await wmill.loadS3File(example_file);
const decoder = new TextDecoder();
const file_content_str = decoder.decode(file_content);
console.log(file_content_str);
// Or load the file lazily as a Blob
let fileContentBlob = await wmill.loadS3FileStream(example_file);
console.log(await fileContentBlob.text());
}
import * as wmill from 'npm:[email protected]';
import { S3Object } from 'npm:[email protected]';
export async function main() {
const example_file: S3Object = {
s3: 'path/to/file'
};
// Load the entire file_content as a Uint8Array
const file_content = await wmill.loadS3File(example_file);
const decoder = new TextDecoder();
const file_content_str = decoder.decode(file_content);
console.log(file_content_str);
// Or load the file lazily as a Blob
let fileContentBlob = await wmill.loadS3FileStream(example_file);
console.log(await fileContentBlob.text());
}
import wmill
from wmill import S3Object
def main():
example_file = S3Object(s3='path/to/file')
# Load the entire file_content as a bytes array
file_content = wmill.load_s3_file(example_file)
print(file_content.decode('utf-8'))
# Or load the file lazily as a Buffered reader:
with wmill.load_s3_file_reader(example_file) as file_reader:
print(file_reader.read())
Certain file types, typically parquet files, can be directly rendered by Windmill.
Take a file as input
Scripts can accept a S3Object as input.
- TypeScript (Bun)
- TypeScript (Deno)
- Python
import * as wmill from 'windmill-client';
import { S3Object } from 'windmill-client';
export async function main(input_file: S3Object) {
// rest of the code
}
import * as wmill from 'npm:[email protected]';
import { S3Object } from 'npm:[email protected]';
export async function main(input_file: S3Object) {
// rest of the code
}
import wmill
from wmill import S3Object
def main(input_file: S3Object):
# Rest of the code
The auto-generated UI will display a file uploader:

or you can fill path manually if you enable 'Raw S3 object input':

and access bucket explorer if resource permissions allow it:

That's also the recommended way to pass S3 files as input to steps within flows.



Create a file from S3 or object storage within a script
You can create a file from S3 or object storage within a script using the writeS3File function from the TypeScript client and the wmill.write_s3_file function from the Python client.
- TypeScript (Bun)
- TypeScript (Deno)
- Python
import * as wmill from 'windmill-client';
import { S3Object } from 'windmill-client';
export async function main(s3_file_path: string) {
const s3_file_output: S3Object = {
s3: s3_file_path
};
const file_content = 'Hello Windmill!';
// file_content can be either a string or ReadableStream<Uint8Array>
await wmill.writeS3File(s3_file_output, file_content);
return s3_file_output;
}
import * as wmill from 'npm:[email protected]';
import { S3Object } from 'npm:[email protected]';
export async function main(s3_file_path: string) {
const s3_file_output: S3Object = {
s3: s3_file_path
};
const file_content = 'Hello Windmill!';
// file_content can be either a string or ReadableStream<Uint8Array>
await wmill.writeS3File(s3_file_output, file_content);
return s3_file_output;
}
import wmill
from wmill import S3Object
def main(s3_file_path: str):
s3_file_output = S3Object(s3=s3_file_path)
file_content = b"Hello Windmill!"
# file_content can be either bytes or a BufferedReader
file_content = wmill.write_s3_file(s3_file_output, file_content)
return s3_file_output
For more info on how to use files and S3 files in Windmill, see Handling files and binary data.
Secondary storage
Read and write from a storage that is not your main storage by specifying it in the S3 object as "secondary_storage" with the name of it.
From the workspace settings, in tab "S3 Storage", just click on "Add secondary storage", give it a name, and pick a resource from type "S3", "Azure Blob", "Google Cloud Storage", "AWS OIDC" or "Azure Workload Identity". You can save as many additional storages as you want as long as you give them a different name.
Then from script, you can specify the secondary storage with an object with properties s3 (path to the file) and storage (name of the secondary storage).
const file = { s3: 'folder/hello.txt', storage: 'storage_1' };
Here is an example of the Create then Read a file from S3 within a script with secondary storage named "storage_1":
import * as wmill from 'windmill-client';
export async function main() {
await wmill.writeS3File({ s3: 'data.csv', storage: 'storage_1' }, 'fooo\n1');
const res = await wmill.loadS3File({ s3: 'data.csv', storage: 'storage_1' });
const text = new TextDecoder().decode(res);
console.log(text);
return { s3: 'data.csv', storage: 'storage_1' };
}
Windmill integration with Polars and DuckDB for data pipelines
ETLs can be easily implemented in Windmill using its integration with Polars and DuckDB to facilitate working with tabular data. In this case, you don't need to manually interact with the S3 bucket, Polars/DuckDB does it natively and in a efficient way. Reading and Writing datasets to S3 can be done seamlessly.
Learn more about it in the Data pipelines section.
Dynamic S3 object access in public apps
For security reasons, dynamic S3 objects are not accessible by default in public apps when users aren't logged in. To make them publicly accessible, you need to sign S3 objects using Windmill's built-in helpers:
- TypeScript:
wmill.signS3Object()(single) /wmill.signS3Objects()(multiple) - Python:
wmill.sign_s3_object()(single) /wmill.sign_s3_objects()(multiple)
These functions take an S3Object as input and return an S3Object with an additional presigned property containing a signature that makes the object publicly accessible.
Signed S3 objects are supported by the Image, Rich result and Rich result by job id app components.
Instance object storage
Under Enterprise Edition, instance object storage offers advanced features to enhance performance and scalability at the instance level. This integration is separate from the Workspace object storage and provides solutions for large-scale log management and distributed dependency caching.

This can be configured from the instance settings, with configuration options for S3, Azure Blob, Google Cloud Storage, or AWS OIDC.

Large job logs management
To optimize log storage and performance, Windmill leverages S3 for log management. This approach minimizes database load by treating the database as a temporary buffer for up to 5000 characters of logs per job.
For jobs with extensive logging needs, Windmill Enterprise Edition users benefit from seamless log streaming to S3. This ensures logs, regardless of size, are stored efficiently without overwhelming local resources.
This allows the handling of large-scale logs with minimal database impact, supporting more efficient and scalable workflows.
For large logs storage (and display) and cache for distributed Python jobs, you can connect your instance to a bucket. This feature is at the Instance-level, and has no overlap with the Workspace object storage.
Instance object storage distributed cache for Python, Rust, Go
Workers cache aggressively the dependencies (and each version of them since every script has its own lockfile with a specific version for each dependency) so they are never pulled nor installed twice on the same worker. However, with a bigger cluster, for each script, the likelihood of being seen by a worker for the first time increases (and the cache hit ratio decreases).
However, you may have noticed that our multi-tenant cloud solution runs as if most dependencies were cached all the time, even though we have hundreds of workers on there. For TypeScript, we do nothing special as npm has sufficient networking and npm packages are just tars that take no compute to extract. However, Python is a whole other story and to achieve the same swiftness in cold start the secret sauce is a global cache backed by S3.
This feature is available on Enterprise Edition and is configurable from the instance settings.
For Bun, Rust, and Go, the binary bundle is cached on disk by default. However, if Instance Object storage is configured, these bundles can also be stored on the configured object storage (like S3), providing a distributed cache across all workers.
Global Python dependency cache
The first time a dependency is seen by a worker, if it is not cached locally, the worker search in the bucket if that specific name==version is there:
- If it is not, install the dependency from pypi, then do a snapshot of installed dependency, tar it and push it to S3 (we call this a "piptar").
- If it is, simply pull the "piptar" and extract it in place of installing from pypi. It is much faster than installing from pypi because that S3 is much closer to your workers than pypi and because there is no installation step to be done, a simple tar extract is sufficient which takes no compute.
Service logs storage
Logs are stored in S3 if S3 instance object storage is configured. This option provides more scalable storage and is ideal for larger-scale deployments or where long-term log retention is important.

S3 proxy
Windmill provides an endpoint that exposes workspace storages via the S3 protocol while hiding the resource credentials and handling advanced permissions:
http://{base_url}/api/w/{workspaceId}/s3_proxy
It is used by DuckDB scripts when accessing S3, but you can use it yourself with any S3 Client:
import { S3Client, PutObjectCommand } from '@aws-sdk/client-s3';
export async function main() {
const base_url = process.env['WM_BASE_URL'];
const workspaceId = process.env['WM_WORKSPACE'];
const tokenParts = process.env['WM_TOKEN'].split('.');
// JWT header and payload constitute the access key ID
const accessKeyId = `${tokenParts[0]}.${tokenParts[1]}`;
// JWT signature is the secret key
const secretAccessKey = tokenParts[2];
try {
const s3Client = new S3Client({
region: 'us-east-1', // Any region
endpoint: `${base_url}/api/w/${workspaceId}/s3_proxy`,
credentials: { accessKeyId, secretAccessKey }
});
const putObjectCommand = new PutObjectCommand({
Bucket: '_default_', // Secondary workspace storage name or _default_
Key: 'hello-world.txt',
Body: 'Hello world!',
ContentType: 'text/plain'
});
await s3Client.send(putObjectCommand);
return 's3:///hello-world.txt';
} catch (error: any) {
const errorMsg = error.$response?.body ?? error.message;
return { success: false, error: errorMsg };
}
}
The proxy uses the Windmill JWT token for authentication. If your storage is of type S3, this proxy simply redirects the request as-is to the true S3 endpoint. For Azure Blob Storage, we have a lightweight translation layer that converts S3 requests to the Azure Blob protocol but we do not recommend relying on it.
Streaming large SQL query results to S3 (Enterprise feature)
Sometimes, your SQL script will return too much data which exceeds the 10 000 rows query limit within Windmill. In this case, you will want to use the s3 flag to stream your query result to a file.