Autoscaling
Autoscaling automatically adjusts the number of workers based on your workload demands.
Autoscaling is available in the Enterprise plan.
Autoscaling configuration
You configure a minimum and maximum number of workers. The autoscaler will adjust the number of workers between the minimum and maximum based on the workload by calling a script which call your underlying infra orchestrator such as Kubernetes, ECS or Nomad. Coming soon, those will be hanlded natively by Windmill without the need for running a job.
Autoscaling is configured in each worker group config under "Autoscaling". It takes the following configuration:
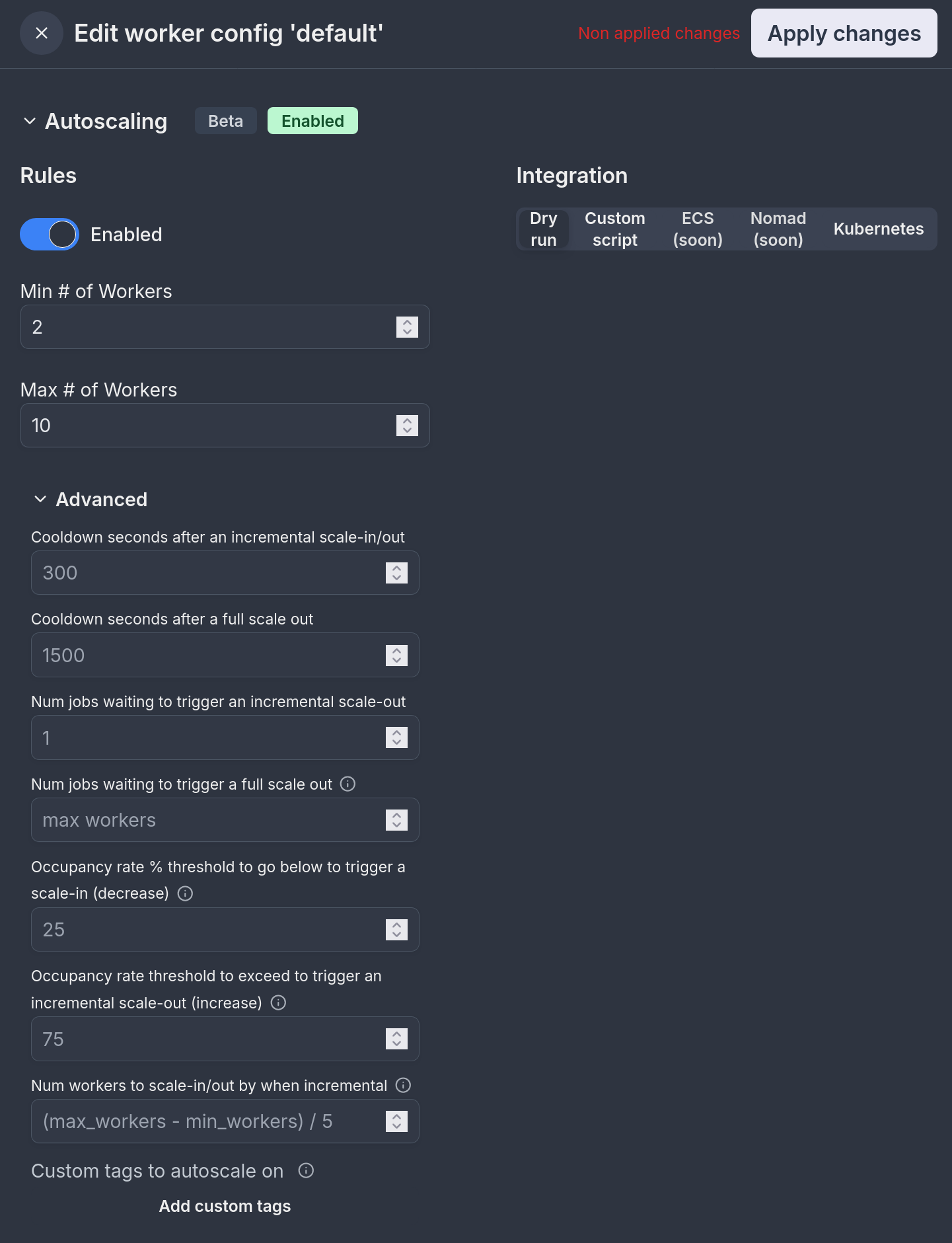
Rules
| Parameter | Description |
|---|---|
| Enabled | Whether autoscaling is enabled for the worker group |
| Min # of Workers | The minimum number of workers to scale down to |
| Max # of Workers | The maximum number of workers to scale up to |
Integration
| Integration Type | Description |
|---|---|
| Dry run | Test autoscaling behavior without making actual changes |
| Custom script | Use your own script to handle scaling workers |
| ECS | Native ECS integration (coming soon) |
| Nomad | Native Nomad integration (coming soon) |
| Kubernetes | Native Kubernetes integration |
Custom script
When using a custom script, you'll need to provide a path to script in the admins workspace, and optionally a custom tag for executing the script.
The arguments that are passed to the script are: worker group, desired workers, reason, and event type. For instance, if you are using Kubernetes, you can use the following script:
worker_group="$1"
desired_workers="$2"
reason="$3"
event_type="$4"
namespace="mynamespace"
echo "Applying $event_type of $desired_workers to $worker_group bc $reason"
# authenticate to the cluster here if needed
kubectl scale deployment windmill-workers-$worker_group --replicas=$desired_workers -n $namespace
Kubernetes
Kubernetes native autoscaling integration can automatically infer the worker-group, namespace and credentials when running within a Kubernetes cluster. This autoscaling will only work if you run your server in the k8s cluster and will only scale workers within the same cluster.
For proper functionality, you need to configure RBAC roles and rolebindings to allow autoscaling from within the pod:
Scale-in prefers idle workers
When scaling in, the integration annotates the worker pods with controller.kubernetes.io/pod-deletion-cost just before lowering the replica count, so the ReplicaSet controller deletes idle pods first instead of picking victims blindly (which could leave a worker mid-job terminating while idle pods stay alive):
- Idle pods get a cost of 0.
- Pods currently running a job get a cost of
10 + age of their oldest running job in seconds(capped at 1 day), so workers on long-running jobs are protected hardest.
This requires the optional list and patch permissions on pods (see the RBAC manifests below). The annotation pass is best-effort and can never fail a scaling operation: if the permissions are missing or anything else goes wrong, a warning is logged and the replica change proceeds as before, without the idle-pods-first preference. The annotation is honored by Kubernetes 1.22+ where the PodDeletionCost feature gate is enabled by default.
Using Helm
In your values.yaml set:
enterprise:
createKubernetesAutoscalingRolesAndBindings: true
Using pure manifests
Sometimes creating a Role/RoleBinding is forbidden by RBAC or rejected by an admission controller, that's why you might want to do this outside this helm release.
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: deployment-scaler
namespace: <windmill-namespace>
rules:
- apiGroups: ["apps"]
resources: ["deployments"]
verbs: ["patch", "get"] # Crucial to include both verbs
# Optional: lets the autoscaler annotate pods with pod-deletion-cost
# so idle workers are deleted first on scale-in
- apiGroups: [""]
resources: ["pods"]
verbs: ["get", "list", "patch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: deployment-scaler-binding
namespace: <windmill-namespace>
subjects:
- kind: ServiceAccount
name: <serviceaccount>
namespace: <windmill-namespace>
roleRef:
kind: Role
name: deployment-scaler
apiGroup: rbac.authorization.k8s.io
You need to bind the role to the correct ServiceAccount which is bound to 'fullname' (the name you gave to your windmill deployment). You can verify which ServiceAccount name you have by running:
kubectl get serviceaccount -n <your-namespace>
Look for the non-default ServiceAccount name.
Verifying configuration
After configuring RBAC using either method above, you can hit "Check Health" to verify everything is configured properly:
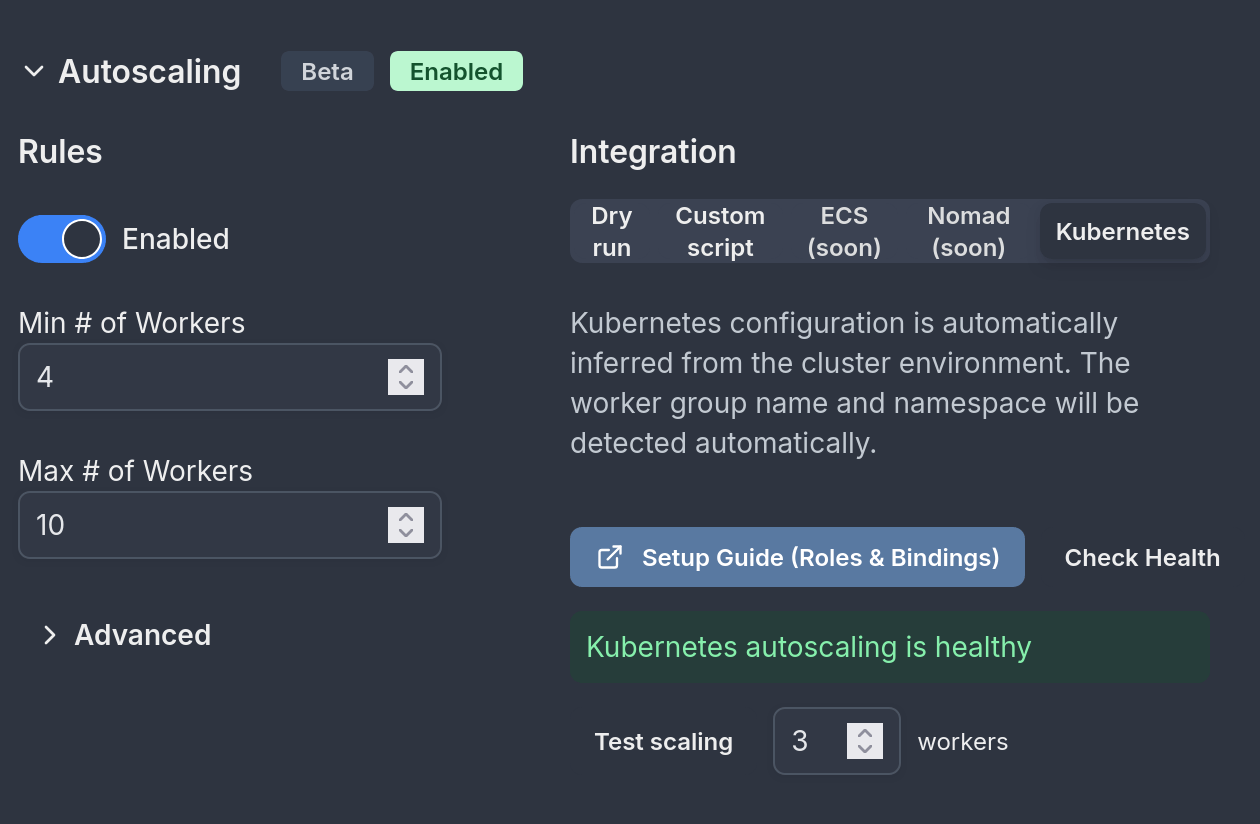
The health check also probes the optional pods permissions used for pod-deletion-cost annotations and logs a non-fatal warning if they are missing: autoscaling stays fully functional, it just loses the idle-pods-first preference on scale-in.
You are ready to go!
For more sophisticated autoscaling designs, refer to the 'Custom script' section above.
Advanced
| Parameter | Description |
|---|---|
| Cooldown seconds after an incremental scale-in/out | Time to wait after an incremental scaling event before allowing another |
| Cooldown seconds after a full scale out | Time to wait after a full scale out event before allowing another |
| Num jobs waiting to trigger an incremental scale-out | Number of waiting jobs needed to trigger a gradual scale out |
| Num jobs waiting to trigger a full scale out | Number of waiting jobs needed to trigger scaling to max workers (Default: max_workers, full scale out = scale out to max workers) |
| Occupancy rate % threshold to go below to trigger a scale-in (decrease) | Default: 25%. When the average worker occupancy rate across 15s, 5m and 30m intervals falls below this threshold, the system will trigger a scale-in event to reduce the number of workers. This helps prevent having too many idle workers. |
| Occupancy rate threshold to exceed to trigger an incremental scale-out (increase) | Default: 75%. When the average worker occupancy rate across 15s, 5m and 30m intervals exceeds this threshold, the system will trigger a scale-out event to add more workers. This helps ensure there is enough capacity to handle the workload. |
| Num workers to scale-in/out by when incremental | Number of workers to add/remove during incremental scaling events (Default: (max_workers - min_workers) / 5) |
| Custom tags to autoscale on | By default, autoscaling will apply to the tags the worker group is assigned to but you can override this here. |
Autoscaling algorithm
The autoscaling algorithm is based on the number of jobs waiting for workers in the queue for the tags that the worker group is listening from (tags can be overriden) and based on the occupancy rate of the workers of that worker group.
The algorithm is as follows:
Every 30s, for every worker group autoscaling configuration:
-
It checks if the current number of workers (
count) is within the allowed range (betweenmin_workersandmax_workers). If not, it adjusts the number to fit within this range. -
If there are more than (
full_scale_jobs_waitingORmax_workersif not defined) jobs , it will increase the number of workers up tomax_workersif there are less (otherwise if workers already above or equal target, do nothing), that's a "full scale-out". Note that full-scale out events are not subject to the cooldown period since they are meant to handle sudden spike. -
The function looks at the last autoscaling event (
last_event) to see if it's too soon to make another change (this is called a cooldown period, defined byfull_scale_cooldown_secondsfor full scale out events orcooldown_secondsfor normal events). -
If there are enough jobs waiting in the queue (more than
inc_scale_jobs_waiting), it will increase the number of workers by aninc_num_workers(default: (max_workers - min_workers) / 5), that's an "incremental scale-out". -
If there aren't many jobs waiting, it looks at how busy the current workers are using the
occupancydata:- If they're not very busy (below
dec_scale_occupancy_rate, default 25%) for a while (occupancy_rate_15s && occupancy_rate_5m && occupancy_rate_30m < inc_scale_occupancy_rate), it will reduce the number of workers byinc_num_workers. - If they're very busy (
occupancy_rate_15s && occupancy_rate_5m && occupancy_rate_30m > dec_scale_occupancy_rate) for a while, it will increase the number of workers byinc_num_workers.
- If they're not very busy (below
The function uses occupancy rates over different time periods (occupancy_rate_15s, occupancy_rate_5m, occupancy_rate_30m) to make decisions, ensuring that changes are based on sustained trends rather than momentary spikes. The 3 values MUST be below or above the threshold to trigger a scale in or out.
When making scale in or scale out, it doesn't just jump to the minimum or maximum. Instead, it increases or decreases by inc_num_workers each time, which is calculated based on the custom parameter provided for incremental scale-in/out (default: (max_workers - min_workers) / 5).
- Every time it decides to change the number of workers, it logs this decision as an "autoscaling event" with an explanation of why it made the change.
The goal is to have just enough workers to handle the current workload (represented by queue_counts) efficiently, without having too many idle workers or too few to handle the jobs.
Autoscaling events
Autoscaling events can be viewed under the worker group details:

Billing
In terms of billing for Windmill Enterprise Edition, Windmill measures how long the workers are online with a minute granularity. If you use 10 workers with 2GB for 1/10th of the month, it will count the same as if you had a single worker for the full month. It's like if in your Windmill setup, the replicas of the worker group would adjust for a given amount of time.